今天小编给大家分享一下C++怎么用libcurl获取下载文件名称及大小的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
显示效果
客户端利用libcurl库下载文件,一般需要预先知道文件名称及大小以及下载进度、下载速度等,以便用户通过界面显示实时下载状态及信息。
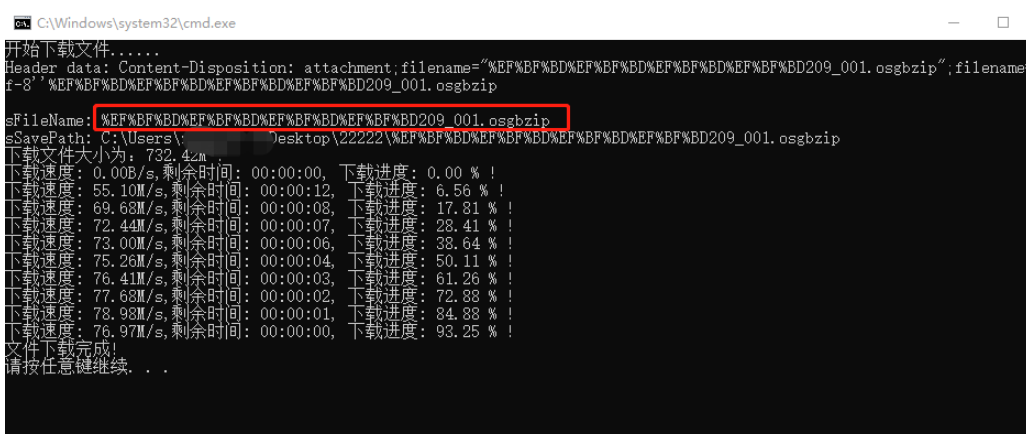
1、从下载url链接获取文件名字
如何通过一个文件的下载链接(url)获取到需要下载的文件名称是我们经常要遇到的一个问题。通常是通过获取header中的Content-Disposition字段来进行解析获取。
Content-disposition 是 MIME 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加的文件。Content-disposition其实可以控制用户请求所得的内容存为一个文件的时候提供一个默认的文件名,文件直接在浏览器上显示或者在访问时弹出文件下载对话框。
该字段包含了两种返回值:
1、inline:将文件内容直接显示在页面
Content-Disposition: inline;filename=hello.jpg2、attachment:弹出对话框让用户下载
Content-Disposition: attachment;filename=hello.jpg可以看出无论是哪种返回值,其中都包括了filename,“=”后面就是我们需要的文件名称。但是有时会出现获取到的文件名称存在中文乱码问题(可能包含非 ASCII 字符)。
2、LibCurl官方示例
Example
static size_t header_callback(char *buffer, size_t size,
size_t nitems, void *userdata)
{
/* received header is nitems * size long in 'buffer' NOT ZERO TERMINATED */
/* 'userdata' is set with CURLOPT_HEADERDATA */
return nitems * size;
}
CURL *curl = curl_easy_init();
if(curl)
{
curl_easy_setopt(curl, CURLOPT_URL, "https://example.com");
curl_easy_setopt(curl, CURLOPT_HEADERFUNCTION, header_callback);
curl_easy_perform(curl);
}3、实例
// Get the file size and name on the server
size_t header_callback(void *buffer, size_t size, size_t nitems, void *userdata)
{
string sHeaderData = (char*)buffer;
string sKey = "Content-Disposition";
std::size_t nFound = sHeaderData.find(sKey);
if (nFound != std::string::npos)
{
printf("Header data: %s
", (char*)buffer);
stringstream ss(sHeaderData);
char cSplit = ';'; // 设定好分隔符号
sKey = "filename=";
vector<string> results; // 用来存储结果
string strResult;
while (getline(ss, strResult, cSplit))
{
nFound = strResult.find(sKey);
if (nFound != std::string::npos)
{
string sFileName = strResult.substr(nFound + sKey.length());
sKey = '"';
nFound = sFileName.find(sKey);
if (nFound != std::string::npos)
{
sFileName = sFileName.substr(1, sFileName.length()-2);
}
m_sFileName = sFileName;
printf("sFileName: %s
", m_sFileName.c_str());
break;
}
}
}
return nitems * size;
}
double getDownloadFileInfo(const string url)
{
CURL *easy_handle = NULL;
int ret = CURLE_OK;
double size = -1;
do
{
easy_handle = curl_easy_init();
if (!easy_handle)
{
ZLOG("curl_easy_init error");
break;
}
// Only get the header data
curl_easy_setopt(easy_handle, CURLOPT_URL, url.c_str());
curl_easy_setopt(easy_handle, CURLOPT_CUSTOMREQUEST, "GET"); //使用CURLOPT_CUSTOMREQUEST
//ret |= curl_easy_setopt(easy_handle, CURLOPT_HEADER, 1L);
curl_easy_setopt(easy_handle, CURLOPT_NOBODY, 1L);
//ret |= curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, nousecb);
curl_easy_setopt(easy_handle, CURLOPT_HEADERFUNCTION, header_callback);
ret = curl_easy_perform(easy_handle);
if (ret != CURLE_OK)
{
char s[100] = {0};
sprintf_s(s, sizeof(s), "error:%d:%s", ret, curl_easy_strerror(static_cast<CURLcode>(ret)));
ZLOG(s);
break;
}
// size = -1 if no Content-Length return or Content-Length=0
ret = curl_easy_getinfo(easy_handle, CURLINFO_CONTENT_LENGTH_DOWNLOAD, &size);
if (ret != CURLE_OK)
{
ZLOG("curl_easy_getinfo error");
break;
}
} while (0);
curl_easy_cleanup(easy_handle);
if (size > 0.0)
{
downloadFileLength = size;
}
return size;
}