这篇文章主要讲解了“java分布式流式处理组件Producer分区的作用是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“java分布式流式处理组件Producer分区的作用是什么”吧!
为什么需要分区
分区的作用
合理的使用存储资源:把海量的数据按照分区切割成一小块的数据存储在多台Broker上。此时能够保证每台服务器存储资源能够被充分利用到。而且小块数据在寻址时间上更有优势~
如果将全部的数据存储在一台机器上,那么要对当前数据做副本的时候,由于服务器资源配置不同,就有可能会出现副本数据存放失败,从而增加数据丢失的可能性。
同时,如果单个文件过大,副本放置时间、内容检索时间都会极大的延长,从而导致Kafka性能降低。
负载均衡: 数据生产或消费期间,生产者已分区的单位发送数据,消费者分区的单位进行消费。 期间,各分区生产和消费数据互不影响,这样能够达到合理控制分区任务的程度,提高任务的并行度。从而达到负载均衡的效果。
刚才我们提到:生产者已分区为单位向Broker发送数据。那么问题来了:
生产者是怎么知道该向哪个分区发送数据呢?
这就是我们接下来要研究的分区策略。
分区策略
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// 如果在消息中指定了分区
if (record.partition() != null)
return record.partition();
if (partitioner != null) {
// 分区器通过计算得到分区
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format(
"The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
// 通过序列化key计算分区
if (serializedKey != null && !partitionerIgnoreKeys) {
// hash the keyBytes to choose a partition
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
// 返回-1
return RecordMetadata.UNKNOWN_PARTITION;
}
}下面的代码可以说是整个分区器的核心部分,可以通过以下的步骤进行说明:
如果在生产消息的时候,已经指定了需要发送的分区位置,那么就会直接使用已经指定的份具体的位置,这样子还节省了也不计算的时间
-
如果在生产者配置
中指定了分区策略类,那么消息生产就会通过已经指定的分区策略类进行分区计算Properties -
否则就会以
作为参数,通过hash取模的方式计算。如果serializedKey
,那么就会采用粘性分区的逻辑。 这在Kafka中属于默认分区器。serializedKey == null -
如果以上情况都没有包含,那么他就会直接返回-1。相当于
的情况。ack=0
在Kafka中分区策略我们是可以自定义的。当然Kafka也为我们内置了三种分区策略类。 接下来我们挑个重点来介绍,来给我们自定义分区器做一个铺垫~

我们已经看到,
DefaultPartitionerUniformStickyPartitionerDefaultPartitioner
在当前版本中,如果没有对
partitioner.class而以下是DefaultPartitioner策略类的核心实现方式,并且标记部分的代码实现其实就是
UniformStickyPartitionerpublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
if (keyBytes == null) {
// 就是这段属于UniformStickyPartitioner的实现逻辑
return stickyPartitionCache.partition(topic, cluster);
}
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}还有一段代码让我们来一起看看
public static int partitionForKey(final byte[] serializedKey, final int numPartitions) {
return Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
}这段代码不管有多复杂,调用方法有多少,但最终我们是能够发现:
-
它的本质其实是在对
做哈希计算,然后通过hash值和分区数做取模运算,然后得到结果分区位置序列化Key
这是一种比较重要的计算方式,但却不是唯一的方式
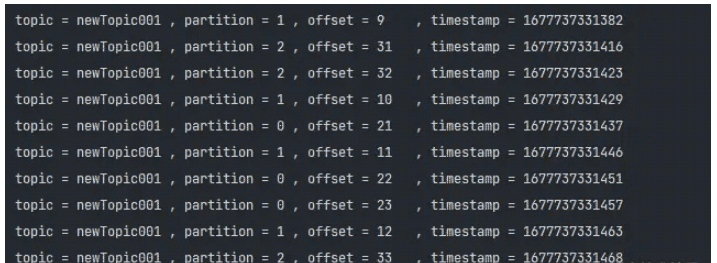
---这是分割线---
接下来继续,我们看看如果无法对序列化Key计算,会是怎么样的计算逻辑?
我们先开始来看一下,是在哪个地方得到的
serializedKeyserializedKey看看下面的这个代码眼熟不?
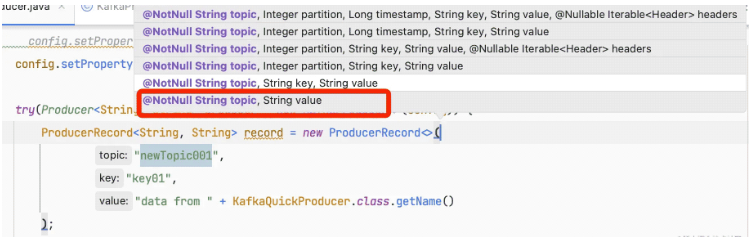
// 生产者生产消息对象
ProducerRecord<String, String> record = new ProducerRecord<>(
"newTopic001",
"data from " + KafkaQuickProducer.class.getName()
);
// KafkaProducer#doSend()
// line994
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());public class StringSerializer implements Serializer<String> {
// 省略。。。
@Override
public byte[] serialize(String topic, String data) {
if (data == null) {
return null;
} else {
return data.getBytes(encoding);
}
}
}从上面的代码来看,基本上能够实锤了:
-
当在生成
对象的时候,如果没有对消息设置key参数,此时序列化之后的key就是个nullProducerRecord 那么当序列化之后的Key为NULL之后,此时分区计算逻辑就会改变。
此时相当于我们已经进入到
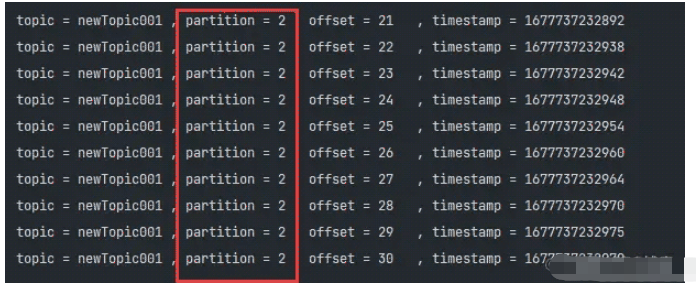
UniformStickyPartitioner根据前面的说法,粘性分区主要解决了消息无Key的分区计算逻辑,那么粘性分区并不是说每次都使用同一个分区
它是通过一个大的Batch为单位,尽量将batch内的消息固定在同一个分区内,这样在很大程度上能够保证:
防止消息无规律的分散在不同的分区内,降低分区倾斜
同时不需要每次进行分区计算,也降低了Producer的延迟
而实现方式是采用ConcurrentMap来进行缓存,感兴趣的大家可以看看
StickyPartitionCache而当Batch内消息满足发送条件被发送出去之后,才会开始再次计算下一个分区,为此在
KafkaProducerpartitioner.onNewBatch(topic, cluster, prevPartition);public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
RoundRobinPartitioner
这是在当前版本中唯一没有被标注的类,未来说不定会成为默认分区策略类,我们不看,就瞄一眼
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k -> new AtomicInteger(0));
return counter.getAndIncrement();
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}这个类的解释,嗯。。你们看那个合适吧~

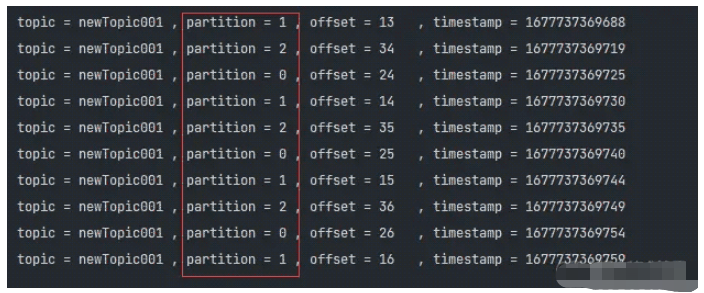
其实这个逻辑非常简单:
-
通过
的方式将每次写入平均分配到不同的分区中AtomicInteger.getAndIncrement() 不同与其他分区策略类,它不关心Key是否为NULL
我们先来做个小实验吧: 将分区策略类修改为
RoundRobinPartitionerconfig.setProperty(
ProducerConfig.PARTITIONER_CLASS_CONFIG,
"org.apache.kafka.clients.producer.RoundRobinPartitioner"
);就这样就能实现,看结果验证~
中间穿插了一点小知识,那么接下来就会进入到我们最后一个环节:尝试自定义分区器
自定义分区器
前面我们也提到过,相信大家没有忘记partitioner.class这个配置
那么接下来就进入到重头戏:自定义分区器实战编码环节。
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
// nothing
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 如果keyBytes == null
// 直接去0号位置
if (null == keyBytes) {
return 0;
}
// 已默认分区策略实现
int numPartitions = cluster.partitionsForTopic(topic).size();
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}
@Override
public void close() {
// nothing
}
}我们就先做的简单一点,主要是想让大家明白自定义分区器的实现:
如果没有给定指定key,那么就默认全部去0号分区
否则就通过key做取模计算
当自定义分区器实现完成之后,接下来我们就需要通过发送者进行验证。当然了,主要还是通过
partitioner.class// 给出关键代码,其他的都是一样的。就不赘述了~~~
config.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, "top.zopx.kafka.partitioner.CustomPartitioner");通过执行之后,我们来看看它的运行效果是否满足我们的预期
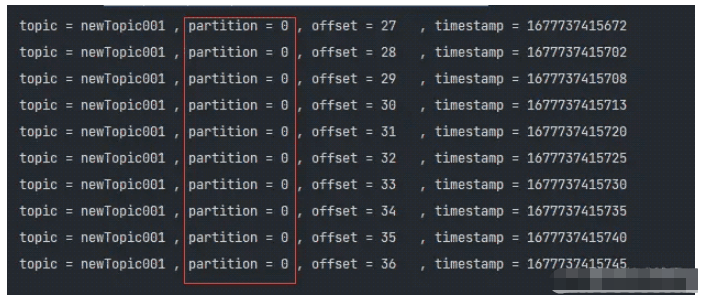
另一种运行结果与默认分区器有Key的情况类似,这里就不再重复贴图